The “duplicate content penalty” is one of the most dreaded concepts in SEO. The idea is that search engines will penalize your website for having duplicated content.
In truth, that isn't likely to happen.
But that doesn’t mean that duplicate content won’t impact your SEO efforts.
In a highly competitive digital landscape, you don’t want to leave anything to chance. It’s important to take a proactive approach towards avoiding and fixing duplicate content issues on your site.
In this article, we’ll go over how duplicate content can impact your rankings, why it happens, and what you can do to prevent and fix it.
What you will learn
- Duplicate content can negatively impact your SEO performance and user experience.
- The causes of duplicate content are mainly technical in nature. They include URL variations, CMS configurations, content syndication and scraping, as well as printable and localized web page versions.
- You can detect duplicate content issues using free tools like Google Search Console.
- Solutions to address content duplication include canonical tags, redirects, sitemaps, consistent internal linking, and proper syndication practices.
What is duplicate content?
Duplicate content refers to identical or nearly identical content that appears on multiple URLs on the web. This can be either within the same website or across multiple sites.
Here's an example to illustrate duplicate content.
Let’s say you run an e-commerce website that sells shoes. You have a product page for a specific model of running shoes, and you create multiple versions for that particular page due to different sorting and filtering options:
www.example.com/shoes/running-shoes
www.example.com/shoes/running-shoes?sort=price
www.example.com/shoes/running-shoes?color=blue
If the content on these pages is essentially the same, with only minor variations in sorting or filtering options, it is considered duplicate content.
How duplicate content impacts SEO
Search engines like Google aim to provide users with the most relevant search results. When they encounter duplicate content, they might have difficulty determining which version is the most authoritative or relevant one.
While there is no such thing as a “duplicate content penalty”—unless you are purposefully and with malicious intent copying content from other sites—your rankings can still suffer from duplicate content.
The problem amplifies when you receive links pointing to different URLs of the same content, diluting your link equity.
As a result, your web pages might not rank as highly in search engine results, and your website's visibility could suffer.
5 Causes of duplicate content
Duplicate content can arise from various factors and causes; most are technical in nature.
Understanding the underlying reasons behind duplicate content is important for addressing and preventing it.
Here are the 5 main causes of duplicate content.
1. URL variations
Your web pages might have duplicate URLs that lead to the same content. This can happen for a number of reasons, such as:
Case sensitivity
For instance, "www.example.com/page" and "www.example.com/Page" might point to the same page, creating duplicate content issues.
Trailing slash
Search engines may treat "www.example.com/page" and "www.example.com/page/"as two separate entities
www vs. non-www
Your website might be accessible through both "www" and "non-www" versions. For instance, "example.com" and "www.example.com" may lead to duplicate content, as search engines treat them as separate URLs.
HTTP vs. HTTPS
If your website is available over both HTTP and HTTPS, search engines might consider them as distinct versions, leading to duplicate content. For example, "http://example.com" and "https://example.com" could be seen as duplicates.
Parameter-based URLs
Ecommerce sites often use parameters for sorting and filtering products. URLs like "www.example.com/products?sort=price" and "www.example.com/products?sort=popularity" can create duplicate content if the page content remains the same except for the sorting criteria.
Session IDs
Some websites use session IDs for tracking users. This can look like “www.example.com/products/shoes” and “www.example.com/products/shoes?sessionid=12345”. When these IDs are appended to URLs as tracking parameters, it can lead to a duplicate version, as multiple users will access the same content through different URLs.
2. CMS configuration
A Content Management System (CMS) can contribute to duplicate content issues when it generates multiple versions or URLs of the same content due to the way it's configured or structured.
Specifically, here's how CMS configurations can cause pages with duplicate content:
Site taxonomies
Many CMS platforms automatically create tag and category pages that list content associated with specific categories or tags. Each category or tag may have its own URL, and if you have content associated with multiple categories or tags, it can lead to multiple URLs pointing to the same content.
For example, suppose you have a blog post about "Healthy Eating" that's categorized under both "Nutrition" and "Wellness." Your CMS might generate the following URLs: www.example.com/category/nutrition/healthy-eating and www.example.com/category/wellness/healthy-eating.
Both URLs lead to the same blog post, causing potential duplicate content issues.
Pagination
CMS platforms often create paginated versions of content when a page contains numerous items, such as blog posts, products, or comments.
Each paginated page typically has a unique URL that differs only by the page number parameter, such as "/page/1," "/page/2," "/page/3," and so on. Search engines might index each paginated page as a separate page.
3. Content syndication and scraping
Content syndication and scraping can both result in duplicate content across multiple websites, potentially outranking the original source.
Let’s clarify the distinction between the two.
Content syndication involves the authorized sharing or distribution of your content on other websites or platforms. It is a legitimate way to expand your content's reach and audience. If not managed properly, it can lead to duplicate content concerns.
Content scrapers, on the other hand, use automated tools to copy content from your website and publish it on their own sites. This practice is typically done without your permission and often violates copyright and intellectual property rights.
4. Printable page versions
Some websites provide a print-friendly version of their articles. These pages typically have separate URLs.
In such cases, URLs may contain keywords like "print," "printable," or "pdf," and they are often similar to the original URL but with added parameters or subdirectories.
Let's say the original URL of an article is www.example.com/article/title/. The URL for the printable version might be www.example.com/printable/article/title/ or www.example.com/article/title/print/.
5. Localization
Duplicate content issues can also arise when you use the same content to target people in different regions.
To cater to different regions that speak the same language, you might have created localized versions of, let’s say, your product pages. Here’s how that can look like:
US: www.example.com/us/products/product-type
UK: www.example.com/uk/products/product-type
Canada: www.example.com/ca/products/product-type
Australia: www.example.com/au/products/product-type
While these product pages might differ slightly in terms of pricing, currency, and shipping information, the core product information, descriptions, and images are essentially the same.
So, if not configured properly, search engines might see these pages as duplicates.
How to fix duplicate content
Duplicate content fixes revolve around specifying which of the duplicates is the right one. This is known as canonicalization.
There are three main methods you can use to tell search engines which of the URLs should become canonical: redirects, rel=”canonical” link annotations, and sitemaps. These solutions become even more effective when combined.
Now let’s go over the different methods you can use to specify a canonical URL and when to use each of them.
Redirects
Use redirects when you want to direct all traffic to one preferred page. Google sees this as a strong signal that the target of the redirect should be the canonical page.
So let’s say your home page can be reached through:
- https://example.com/
- https://www.example.com
- https://home.example.com
You can pick one preferred URL structure and redirect all traffic from the other pages to that one. All redirection methods have the same effect.
rel=”canonical” annotations
A rel=”canonical” link element is another strong signal that the specified page should be the canonical one.
You can add a rel=”canonical” link element in the HTML code or the HTTP header of a duplicate page. The URL of the original page is present alongside the link element.
This tells search engines that the page that contains the rel=”canonical” attribute is a duplicate of the specified page.
Sitemaps
Choose your canonical URLs and add them to a sitemap. This is a simple way you can let Google know which pages are important to you.
You can create a sitemap manually if your site has less than a few dozen links or use the sitemap generated by your CMS.
Then, submit your sitemap in Google Search Console. Under Indexing > Sitemaps > Add a new sitemap

Other methods to fix and prevent duplicate content
On top of setting a canonical URL, there are other strategies at your disposal to tackle and prevent duplicate content issues
Implement effective content syndication strategies
Ensuring proper content syndication is another essential preventive measure for duplicate content issues. Using canonical tags and linking back to the source can prevent duplicate content issues from external sources, such as content syndication and scraping.
Properly configure your CMS
In case your duplicate content issues arise due to CMS configurations, then you’ll have to change the configurations. For example, are there session IDs in your URLs or are you using comment pagination? Turn to your system settings to disable these features.
By properly configuring your CMS, you can prevent future duplicate content issues as well.
Improve internal linking structure
Maintaining a strong internal link structure across your website also ensures that search engines can easily identify the original source of content and navigate your site effectively.
By creating a clear hierarchy and linking patterns, you help search engines understand the relationship and importance of pages within your website.
Report duplicate content
If your duplicate content issues are due to someone having copied your content without permission, then they are breaking copyright laws and you can report it to Google.
Google will review it and potentially take the duplicate content down. This is not the same as taking legal action.
Write unique content
Another extra tip to avoid duplicate content is to write unique content. For instance, you can write unique product descriptions and articles for each localized version of your website.
While this might seem like a task that would take a lot of time, it's easier with the help of AI. AI tools like Surfer AI can help you create localized and unique content that fits your brand voice.
With Surfer AI, you can create content in 7 languages: English, German, Polish, Dutch, French, Spanish, and Danish.
Start by specifying the preferred location and language in the Content Editor. The AI will analyze the SERPs in that region and write an article based on what ranks.
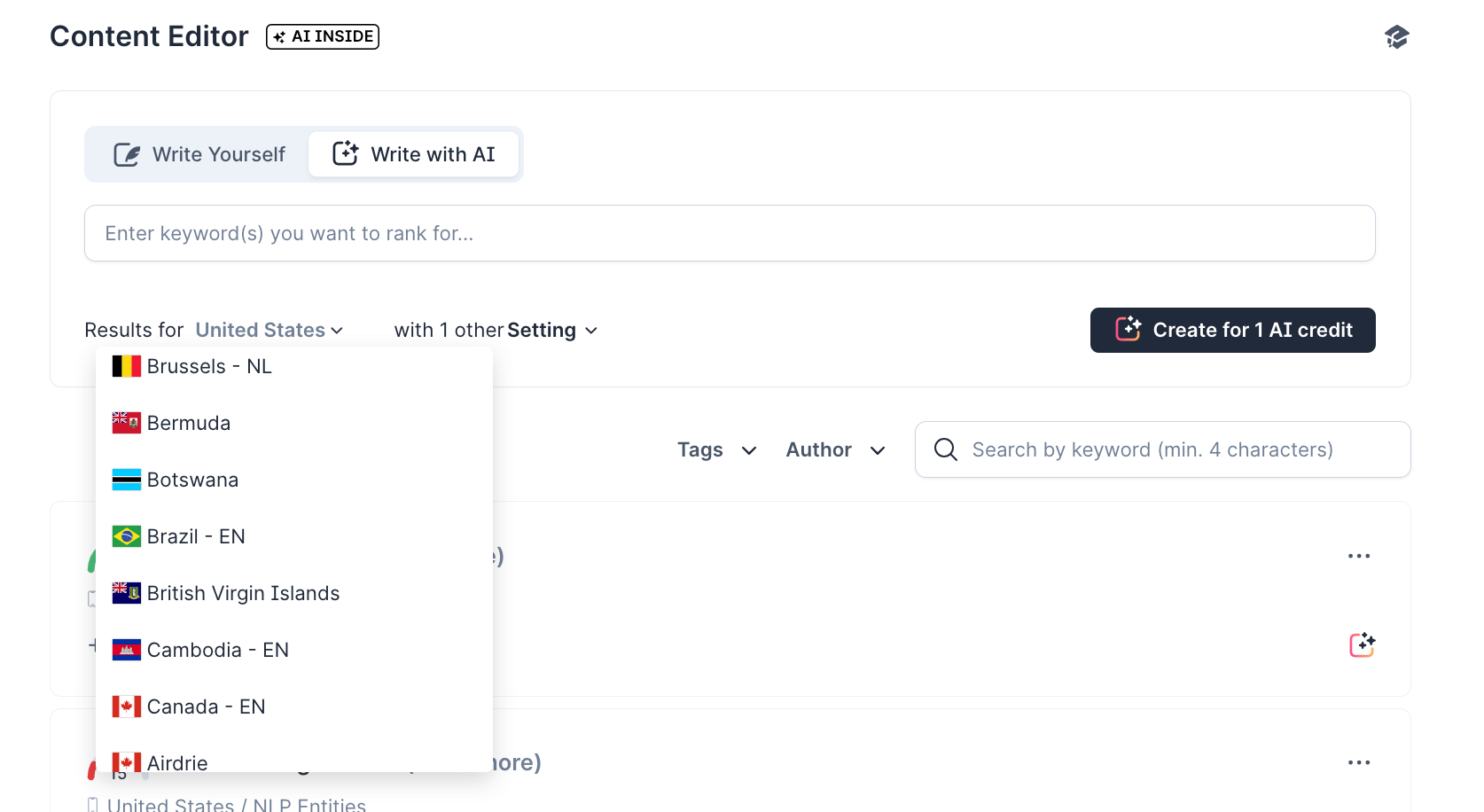
This way, you can easily create unique content for each localized version of your site.
Detecting duplicate content
To find duplicate content on your site, you can use the Google Search Console Index Coverage report. There, you can see which pages on your website Google has indexed, which ones it has not, and any errors or warnings.
To identify duplicate content, look at the following messages:
Duplicate without user-selected canonical: These pages on your website are duplicates of another page, but they do not have a canonical tag. Google has chosen another version of those pages to show in search results.
Duplicate, Google chose different canonical than user: This can occur when you've added a canonical tag to a page, but Google's algorithms believe another version of the page should be treated as canonical.
Duplicate, submitted URL not selected as canonical: Similar to the above, this happens when you have submitted a URL to Google Search Console, but Google has chosen to index a different page instead.
You can see a list of the pages affected by these issues by clicking on the messages.
Based on what’s causing the issue, you can implement the above fixes, such as setting up 301 redirects, adding rel=”canonical” attributes, and submitting a fresh sitemap to Google.
To identify duplicate content that may exist outside of your websites, you can perform a simple Google search. Take a unique sentence or phrase from your content, enclose it in quotation marks, and enter it into the Google search bar.
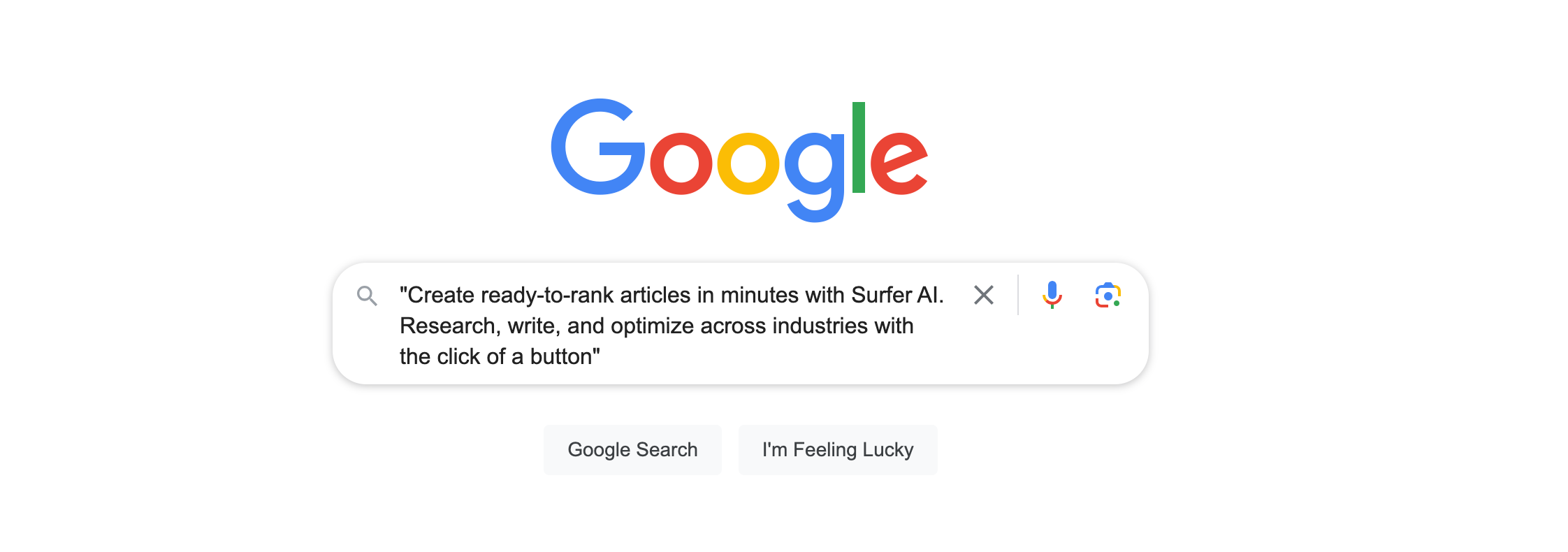
This search technique helps you find exact matches of your content on the web.
However, this only works if you have a relatively small website with not many pages. This way, you can detect content scrapers.
If your website has multiple pages, then you might need to use a tool such as Screaming Frog or Coypscape to find duplicate or near-duplicate content across the web.
Key takeaways
- Duplicate content can negatively impact your search engine rankings by diluting the equity of your links.
- Duplicate content can also confuse search engines as they won’t know which version of the URL to index. They will try to index the more authoritative page, but that won’t always align with the page you consider the most important.
- Canonicalization is the main solution to duplicate content. It includes a number of methods you can use to signal to search engines which page to make canonical.
- You can signal to search engines which URL is the original and which is a duplicate by using redirects, canonical tags, and submitting an updated sitemap.
- You can apply a number of other methods to prevent and fix duplicate content, such as properly configuring your CMS, implementing effective content syndication strategies, improving your internal linking structure, reporting duplicate content to Google, and writing unique content for each localized version of your site.
Conclusion
In this article, we looked at the truth behind duplicate content and the myths surrounding it.
Search engines will not directly penalize you for having the same content accessible through multiple URLs on your website or across websites.
However, search engines like Google look at all the duplicate pages and serve the page they deem most appropriate. This can lead to having the wrong pages indexed, which can negatively affect the user experience.
Plus, when others link to duplicate pages of your content, you will miss out on a lot of that link equity being diluted across several pages.
The solutions to duplicate content are mainly technical but easy to implement. We recommend not neglecting this meaningful addition to your SEO strategy.

